Bureau of Labor Data, it's approximated that around 11.5 million information scientific research tasks will certainly be created by 2026. The scale of big data is truly astonishing, and it has already linked itself in core elements of personal and company life. Consumers are ending up being a lot more familiar with their information personal privacy civil liberties and information routines, while companies https://simonvjsn197.weebly.com/blog/data-removal-what-it-is-why-it-matters-crucial-attributes-2023 have actually leveraged such intel to excellent impact. According to Julius Černiauskas, the Chief Executive Officer at Oxylabs, a lot more machine learning designs will be released in the field. Moreover, according to Tomas, generative AI is significantly extensively made use of in company usage cases.
- Financial services, advertising and marketing, retail, medical care, amusement, and several various other sectors are all making use of internet scuffing and different data to get an one-upmanship.
- Relying on the top quality and the level of error taking care of reasoning present in the computer, this failing can lead to error messages, damaged result or even program collisions.
- And while its advantages are legitimate for some services, others are using it to advertise illegalities in the cyber world.
So the already wonderful numbers are growing at an ever-increasing rate. You could still feel doubtful regarding the future of web crawling, so let's very first consider the current picture of what the data looks like. You'll be astonished by exactly how the world of data is strained with info and how the amount of that information is expanding per second. However, numerous are too fast to overestimate the current abilities of AI, which causes them spreading out the deceptive info or code it in some cases produces. One instance of that is StackOverflow's ban on ChatGPT after a flooding of incorrect answers.

Anti-scraping Protections In 2023
Information scratching commonly involves disregarding binary information, show format, repetitive labels, unnecessary discourse, and various other details which is either unnecessary or impedes automated processing. To navigate these obstacles, we and much of our customers have improved our anti-bot evasion procedures. This includes enhancing fingerprint technology, developing sophisticated browser-based automation, and transitioning from data centre proxies to a lot more innovative residential proxies. When I first introduced the business, our main focus was offering SERP scraping customers. While back then, information centre proxies were the preferred approach, it's currently almost difficult to scratch Google at scale utilizing them, and it has ended up being prohibitively costly for the typical local business owner.
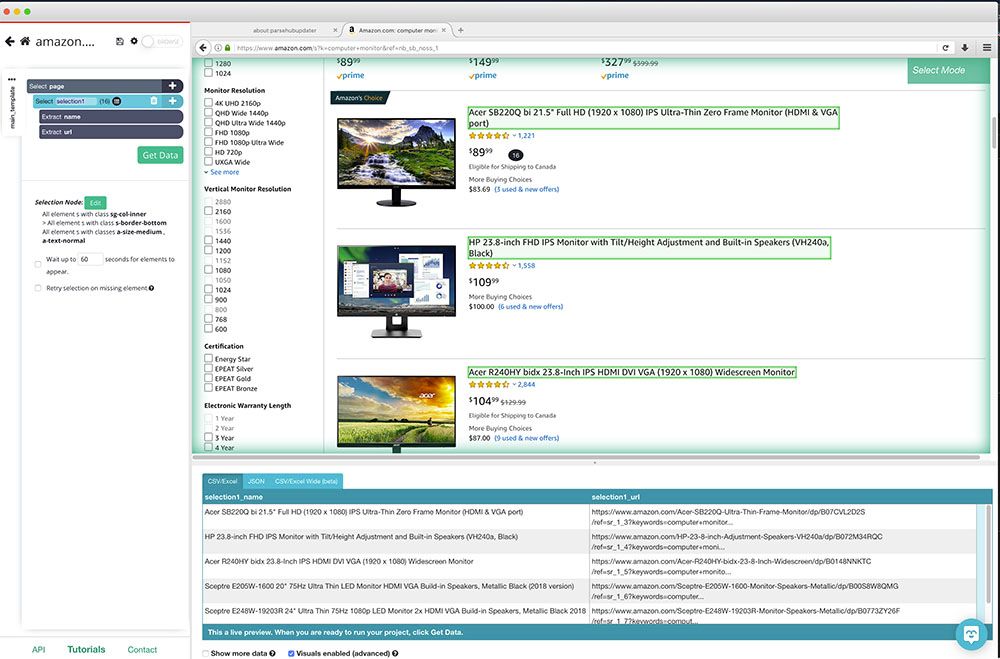
Until the advent of data scratching, there were tons of information idling away in older systems, and the thought of extracting them put simply you off. This procedure is automated which is why it's called a scraper bot system. You appreciate scuffed information for as long as you want and as far as the robot is still active. Information scratching is the process of utilizing computer system software application to get the output of information created by another computer system.
Functionalities Of Web Scuffing
Some companies, such as Oxylabs, have been broadening theirproxyservices even more, entering 2023 with the introduction ofWeb Unblocker. Others, such as Bright Information, launchedmarket knowledge tools by acquiring Market Beyond. Zyte opted for a complete all-in-one APIsolution instead at the suggestion of the new year. All these actions are linked by the motivation for internet scratching companies to come to be something more than internet data service providers. Information scuffing is utilized for numerous objectives throughout industries, such as marketing research, business automation, information analysis, and decision-making. It has found applications in markets such as finance, retail, healthcare, and media, where it is employed to observe costs, identify patterns, and analyze consumer actions.
Code.org Presses Washington To Make Computer Science a High ... - Slashdot
Code.org Presses Washington To Make Computer Science a High ....
Posted: Fri, 20 Oct 2023 01:25:00 GMT [source]
This might be a barrier for local business and organizations with restricted budgets. Even if the information scraped is public or anonymized, it's vital to consider how that information might be Tailored business intelligence services made use of to infringe upon an individual's right to privacy. Organizations should comprehend and appreciate the personal privacy of all entailed when conducting internet scuffing activities to prevent unintentional Data-driven insights for your business offenses of people' legal rights and ensure accountable use such modern technologies. Site scratching devices can help you gather and take advantage of this information effectively. Exactly how I get ChatGPT to access the net Do you desire for allowing ChatGPT roam the web?
Real-time Internet Scuffing And Information Streaming
It's one of the most effective methods for getting online information and, in some cases, sending that information to one more website. Bear in mind, each Facebook scraping job must follow Facebook's plans and regard customer personal privacy. Right here are the advantages that an analysis of the information accumulated with scuffing can offer your company. A personal proxy is released to a single user, who thinks control over the proxy. A shared proxy is where a number of individuals share proxies and their costs. As a business owner, you can overcome these challenges with accessibility to top quality and dependable information concerning the market, which you can locate on the internet.