Recognize The Difference: Internet Crawler Vs Web Scrape As far as terms web or information are concerned, if the term web is used, it consists of the Internet. Unless it includes word data, the Net does not always have to be associated with the creeping activities. Scalability of a crawler system is of considerable relevance while rolling it out. Data scuffing is much easier to set up, as it can be tailored to complete any type of specific task and get over any type of prospective barriers that may occur while doing so. Information creeping, on the various other hand, needs extra sophisticated modifications of the spiders to provide optimal protection of the required pages. Restriction your information scraping or crawling frequency and speed to avoid overloading or crashing the web servers. Test and debug your code prior to running it on the real web pages or records, handling any kind of mistakes or exceptions that might occur during the information removal process. Shop and handle your information in a safe and secure and orderly way with suitable formats, such as CSV, JSON, or SQL. Additionally keep in mind to backup your information frequently and delete or archive any type of outdated or pointless information. Information crawling got its name from spiders who crawl around the properties. A digital "crawler" can creep around the Net, indexing web pages of numerous websites. So initially you produce a spider that will certainly outcome all the web page URLs that you appreciate - it can be pages in a specific category on the website or in details parts of the site. Or possibly the link requires to contain some sort of keyword phrase for instance and you gather all those URLs - and afterwards you develop a scraper that removes predefined information fields from those web pages. It is currently clear that data scratching is vital to a business, whether it is for client acquisition or service and profits development. Creeping is frequently made use of to index web sites or accumulate big quantities of information for analysis.
Scraping or Stealing? A Legal Reckoning Over AI Looms - Hollywood Reporter
Scraping or Stealing? A Legal Reckoning Over AI Looms.
Posted: Tue, 22 Aug 2023 07:00:00 GMT [source]
Information Scuffing For Organization
By doing this, it doesn't necessarily need to be drawn from the web alone, as it can in fact be taken from any type of area where information exists. This Great site doesn't draw solely from the internet, it can be extracted from anywhere that information exist. This could include spreadsheets, storage space gadgets, etc, anywhere data exist in any type of type.Meta To Lay Off Employees in Metaverse Silicon Unit Tomorrow - Slashdot
Meta To Lay Off Employees in Metaverse Silicon Unit Tomorrow.
Posted: Tue, 03 Oct 2023 07:00:00 GMT [source]
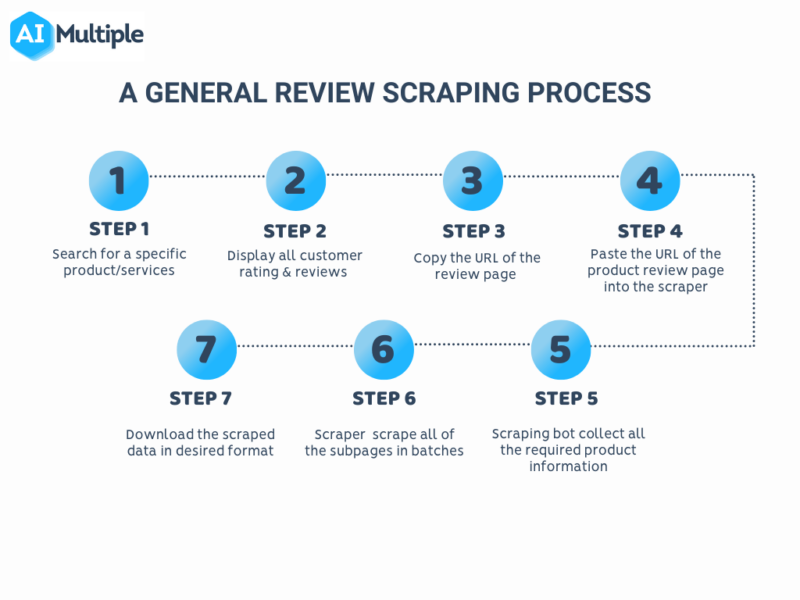
Tl; Dr: Data Scraping Vs Information Creeping
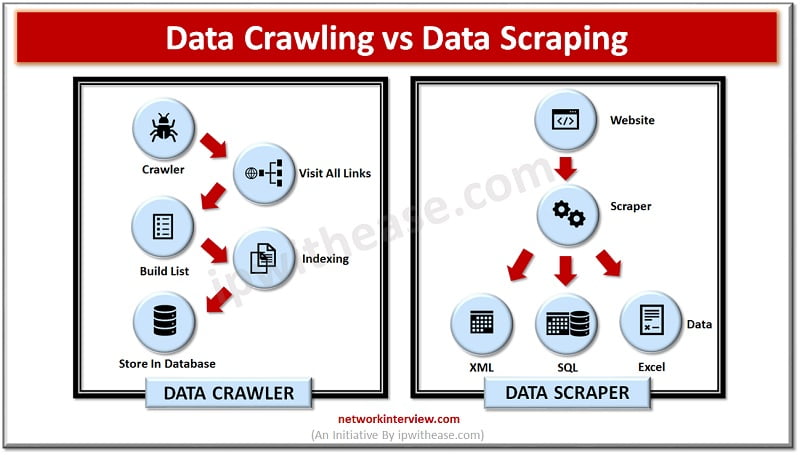
Generally, irrespective of the techniques included, we refer to the access of data from the website as scuffing, and this is a significant misconception. While both internet creeping and information scratching are crucial techniques of recovering information, the info required and the processes associated with the corresponding techniques are different in several methods. Whereas scratching is preferred in some cases, crawling is the go-to choice in others. You can choose either, depending upon what sort of information you're wanting to dig up. We may say that information Take a look at the site here creeping's function is to manage massive information sets where one constructs crawlers that creep to the inmost website of a website.- As an example, it may be an HTML element framework for a particular web page.Nevertheless, the data gathered this way will be available for the following study or data collection procedure, making it better suited for long-term usage.Hence, information de-duplication is an integral part of web data creeping service.